http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html
下載hadoop(2.5.0)
1: http://www.apache.org/dyn/closer.cgi/hadoop/common/
安裝jdk
1: sudo add-apt-repository ppa:webupd8team/java
2: sudo apt-get update
3: sudo apt-get install oracle-java7-installer
安裝套件
1: sudo apt-get install ssh
2: sudo apt-get install rsync
設定變數
1: vim ~/.bashrc 加入下面
export JAVA_HOME=/usr/lib/jvm/java-7-oracle
export PATH=$PATH:$JAVA_HOME/bin:/home/jimmy/work/hadoop/bin
存完 , 輸入以下指令生效
source ~/.bashrc
2: vim etc/hadoop/hadoop-env.sh 修改加入下面參數
export HADOOP_PREFIX=/home/jimmy/work/hadoop
export JAVA_HOME=/usr/lib/jvm/java-7-oracle/
export HADOOP_COMMON_LIB_NATIVE_DIR=/home/jimmy/work/hadoop/lib/native
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=/home/jimmy/work/hadoop/lib/native"有三種mode可以使用
1:Local (Standalone) Mode
2:Pseudo-Distributed Mode
3:Fully-Distributed Mode
目前只使用Local (Standalone) Mode
1:mkdir input
2:cp etc/hadoop/*.xml input
3:bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar grep input output 'dfs[a-z.]+'
4: cat output/*
這時候一定會有錯誤訊息
jimmy-VirtualBox/127.0.1.1 to localhost:9000 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
hadoop起來後才不會有錯誤,但是官方文件挺無言的.
修改設定檔
1: vim etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
2: vim etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
產生公/私鑰
1: ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
2: cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
啟動hadoop
1: bin/hdfs namenode -format
2: ./sbin/start-all.sh
(如果你看到以下錯誤
hadoop/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard
代表你沒設定
export HADOOP_COMMON_LIB_NATIVE_DIR=/home/jimmy/work/hadoop/lib/native
)
3: 輸入 http://localhost:50070/ 確認hadoop起動

4:建立資料夾
(1): bin/hdfs dfs -mkdir /user
(2): bin/hdfs dfs -mkdir /user/jimmy
5: 複製xml 到input
(1): bin/hdfs dfs -put etc/hadoop input
6: run example
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar grep input output 'dfs[a-z.]+'
7: copy hdfs
bin/hdfs dfs -get output output
8: cat output/* 你會看到
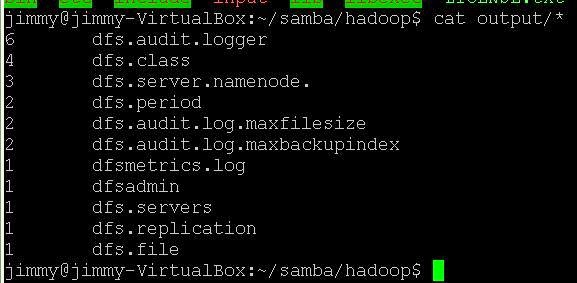
9: ./sbin/stop-all.sh
ps: 可以透過 export HADOOP_ROOT_LOGGER=DEBUG,console 看看錯誤訊息
default值: export HADOOP_ROOT_LOGGER=INFO,console
Nice and good article. It is very useful for me to learn and understand easily. Thanks for sharing your valuable information and time. Please keep updating Hadoop administration Online Training Hyderabad
回覆刪除